Abstract
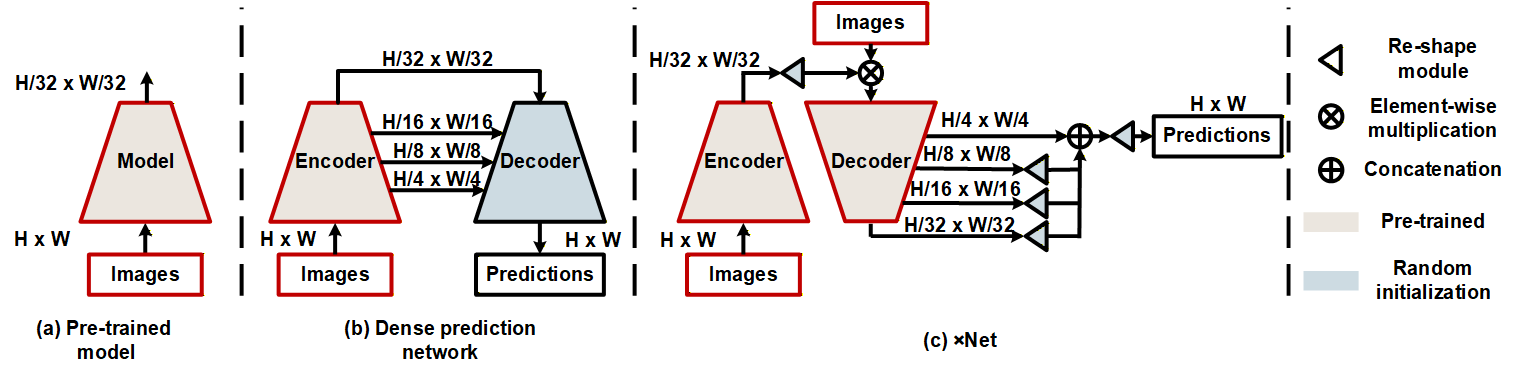
Encoder-decoder networks are commonly used model architectures for dense prediction tasks, where the encoder typically employs a model pre-trained on upstream tasks, while the decoder is often either randomly initialized or pre-trained on other tasks. In this paper, we introduce ×Net, a novel framework that leverages a model pre-trained on upstream tasks as the decoder, fostering a ``pre-trained encoder × pre-trained decoder'' collaboration within the encoder-decoder network. ×Net effectively address the challenges associated with using pre-trained models in the decoding, applying the learned representations to enhance the decoding process. This enables the model to achieve more precise and high-quality dense predictions. By simply coupling the pre-trained encoder and pre-trained decoder, ×Net distinguishes itself as a highly promising approach. Remarkably, it achieves this without relying on decoding-specific structures or task-specific algorithms. Despite its streamlined design, ×Net outperforms advanced methods in tasks such as monocular depth estimation and semantic segmentation, achieving state-of-the-art performance particularly in monocular depth estimation.

Method
Overview of the image classification model (left), encoder-decoder network (middle), and our ×Net (right). The pre-trained model represents the commonly used hierarchical structure. The channels are scaled with model size; detailed settings are available in our repository.
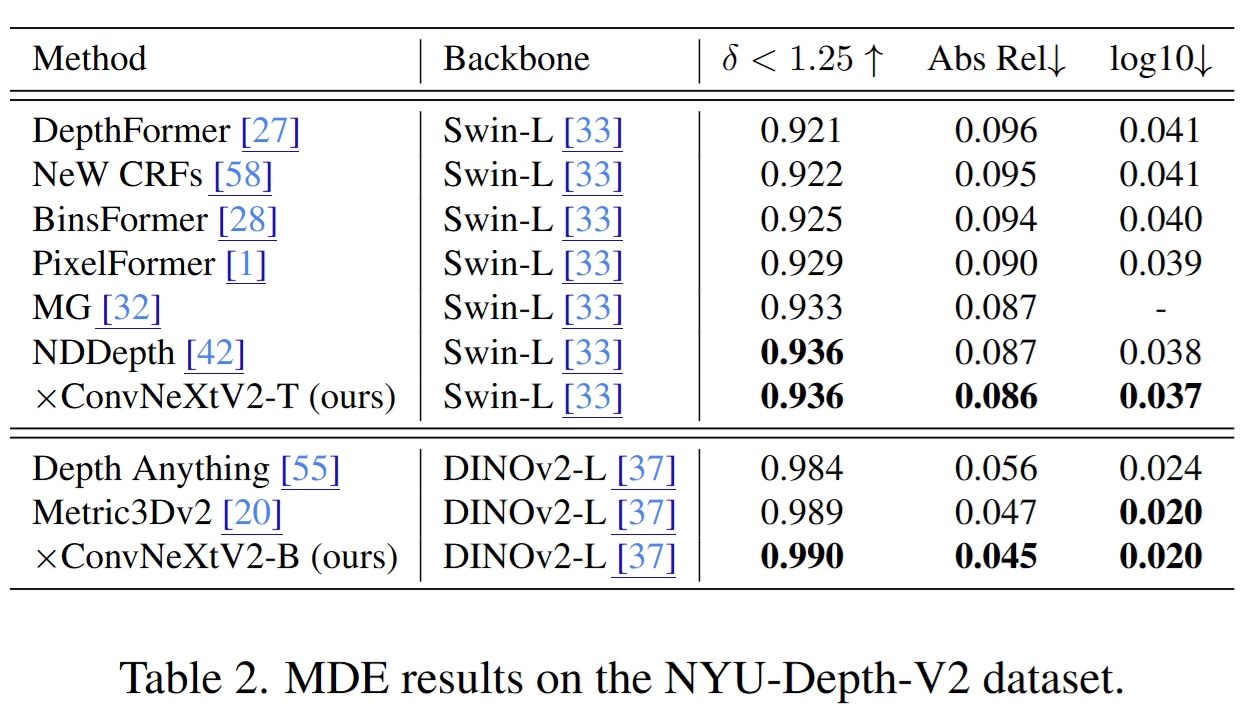
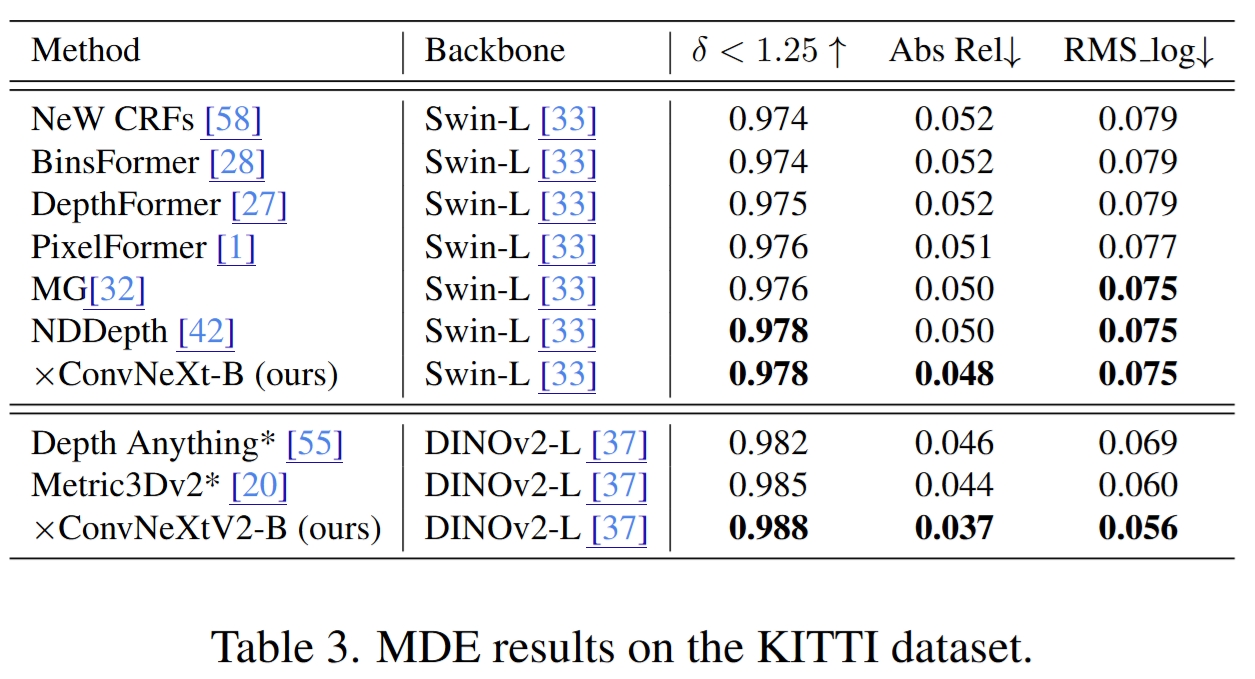
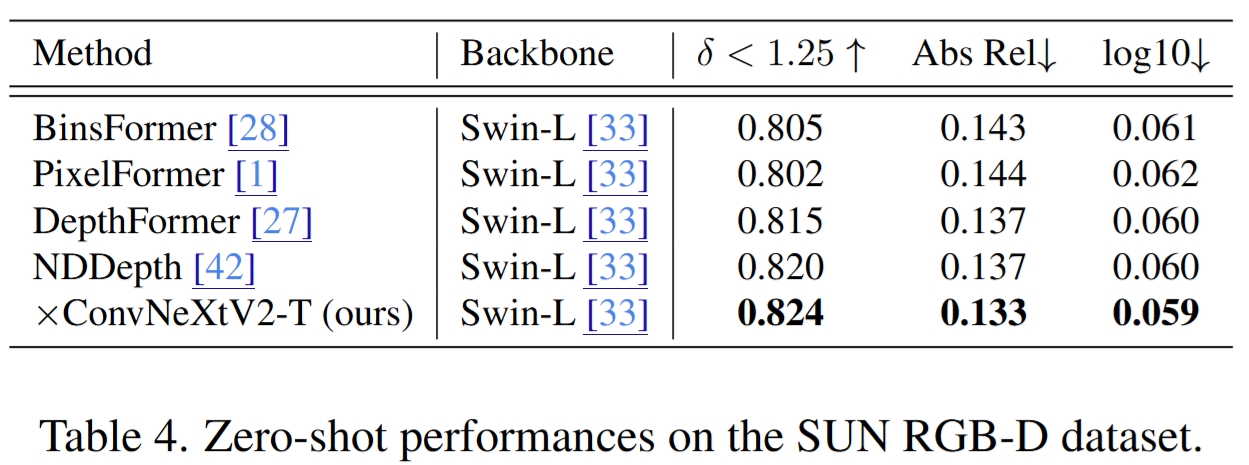
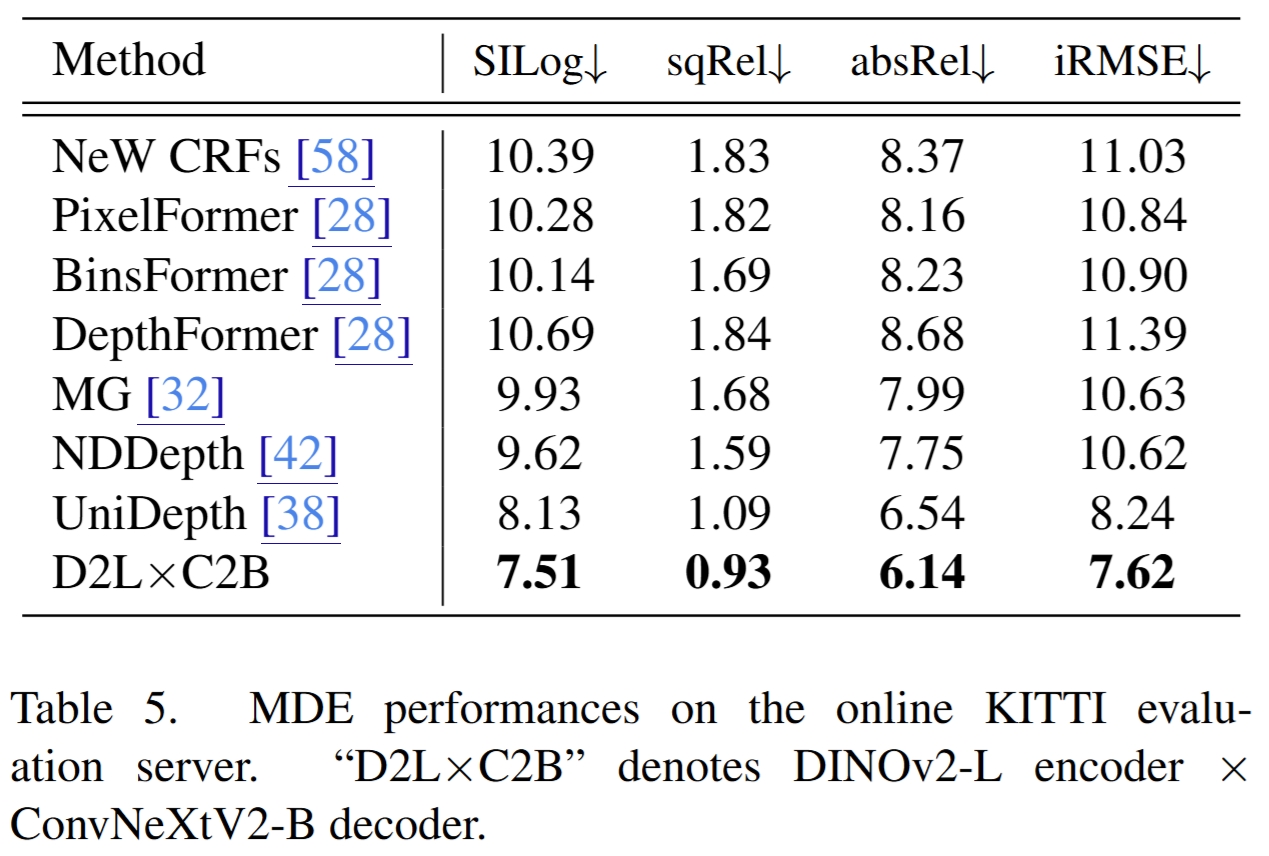
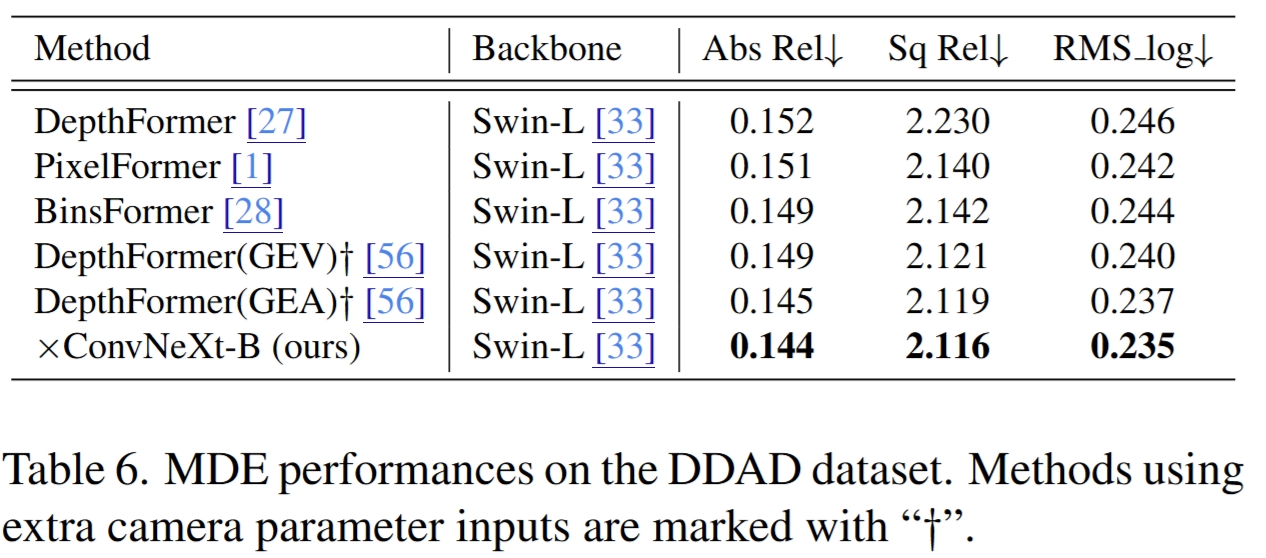
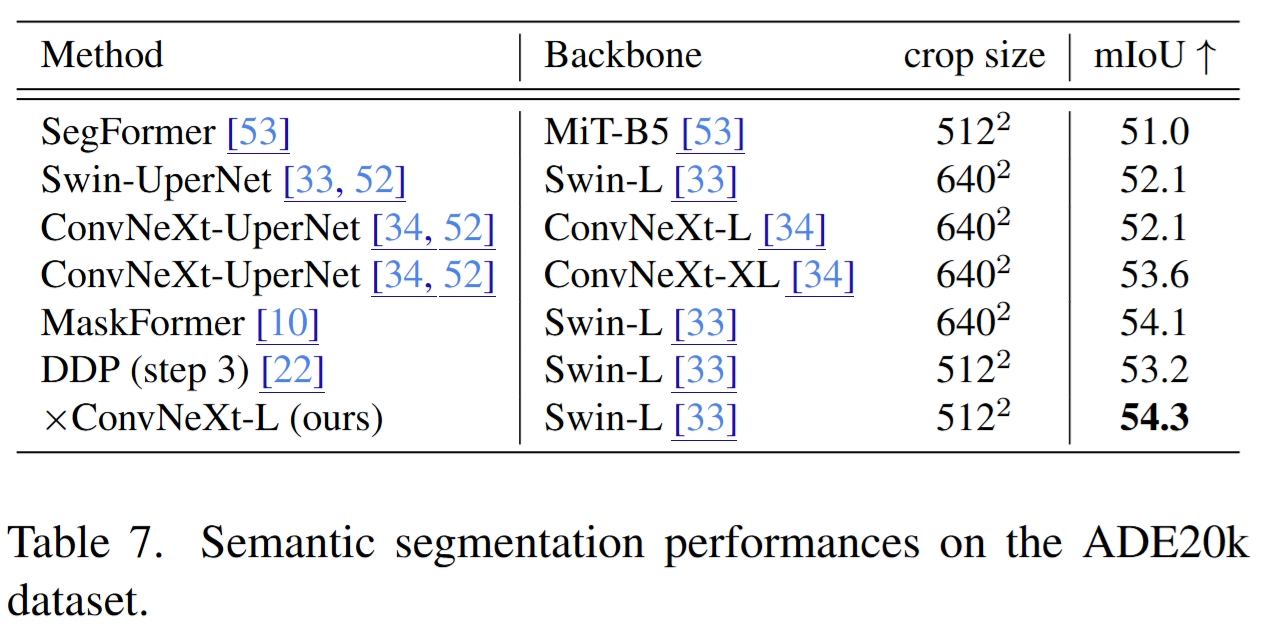
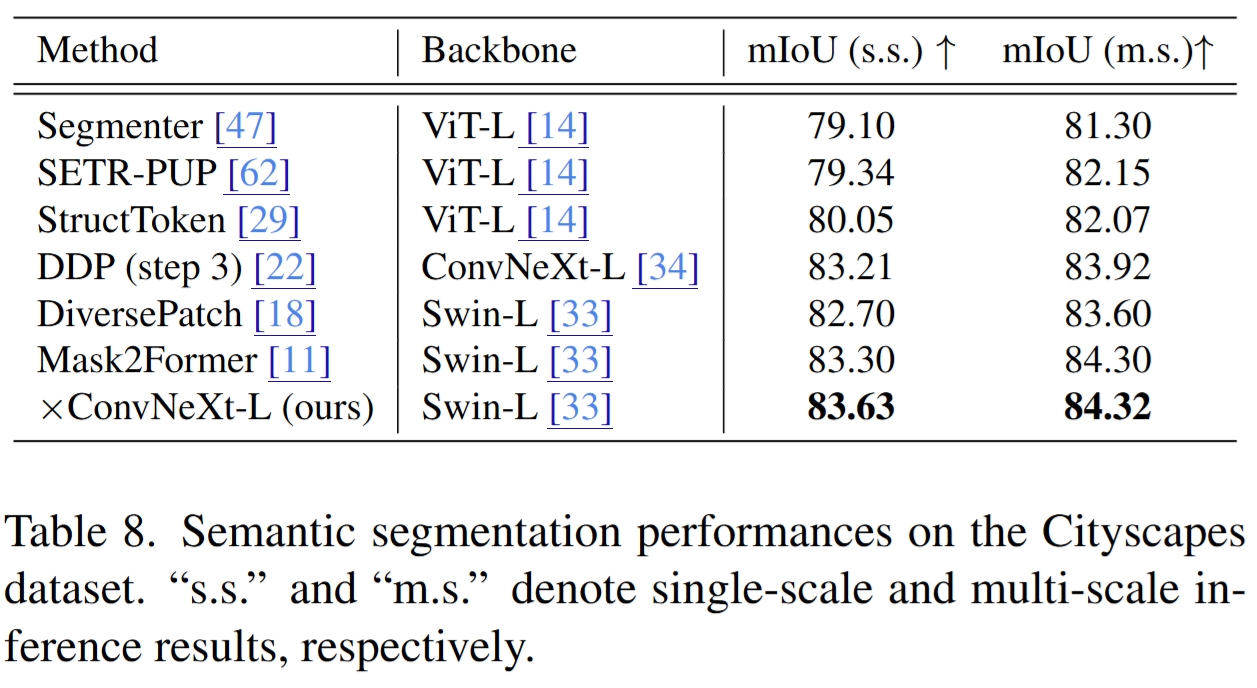
Main Results
Quantitative comparison
Qualitative comparison



