|
Ph.D. student from the Sugiyama-Yokoya-Ishida Lab at the University of Tokyo, Department of Complexity Science and Engineering, advised by Prof. Naoto YOKOYA. I am a part-time worker of the Geoinformatics Team at the RIKEN Center for Advanced Intelligence Project (AIP). |

|
|
|
|
|
|
Chao Ning, Minghe Shen, Naoto Yokoya CVPR, 2026 Project We study monocular metric depth estimation (MMDE) without camera intrinsics at training or inference. When focal length and scene depth vary together, depth changes are difficult to perceive from image, yet the edge-frequency statistics exhibit systematic, scale-correlated shifts. Building on this observation, we introduce a spectral quantile estimator (SQE) that analyzes the Fourier spectrum of a predicted edge map and outputs a single score used as a proxy for metric scale. Consequently, we propose MD2E, a method that models depth-to-edge cues by deriving edge targets from depth annotations, calibrating metric scale using the spectral score, and using edge predictions to regularize depth boundaries while producing metric depth. Across diverse cameras and datasets, MD2E achieves state-of-the-art monocular metric depth in both zero-shot and fine-tuning settings without camera metadata. |

|
Chao Ning, Wanshui Gan, Weihao Xuan, Naoto Yokoya ICRA, 2026 Paper Project We present ×Net, a simple framework that enables collaboration between a pretrained encoder and a pretrained decoder by directly leveraging pretrained models in the decoder, delivering state of the art results on dense prediction tasks such as monocular depth estimation and semantic segmentation without task specific decoding structures. |
|
Chao Ning, Weihao Xuan, Wanshui Gan, Naoto Yokoya IROS, 2025 Paper Project We introduce LR2Depth, a monocular depth estimation method that applies large kernel convolution on low resolution feature maps to aggregate large region context efficiently, achieving state of the art accuracy on NYU Depth v2, KITTI, and SUN RGB D while running about twice as fast as prior methods. |
|
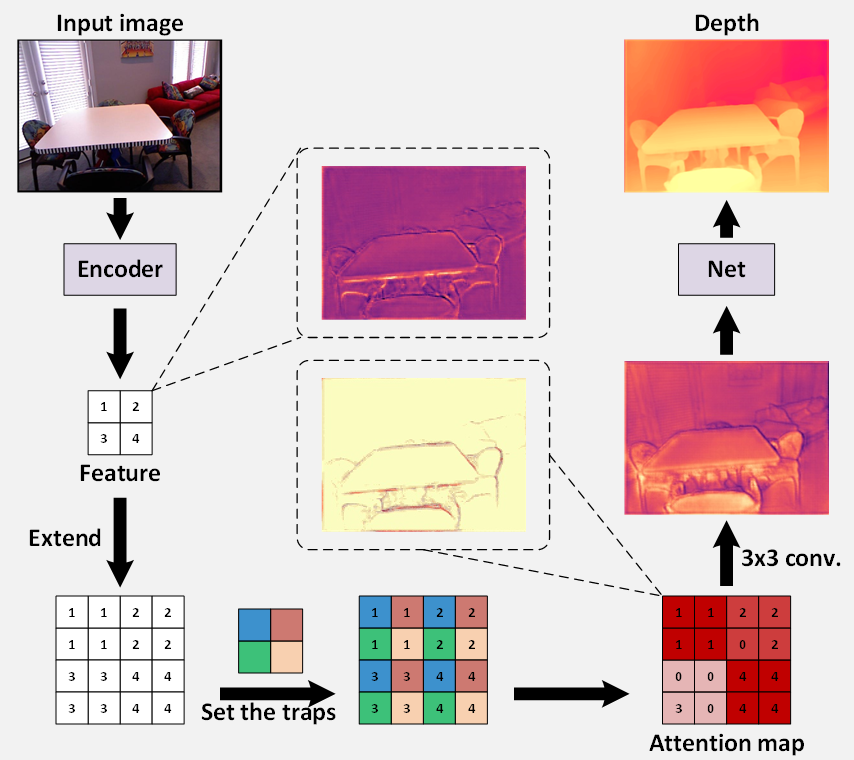
Chao Ning, Hongping Gan CVPR, 2023 Paper Code We propose a linear complexity trap attention for monocular depth estimation from a single image that uses depthwise convolution to capture long range context within a ViT encoder and decoder, achieving state of the art results on NYU v2 and KITTI with far fewer parameters. |
|
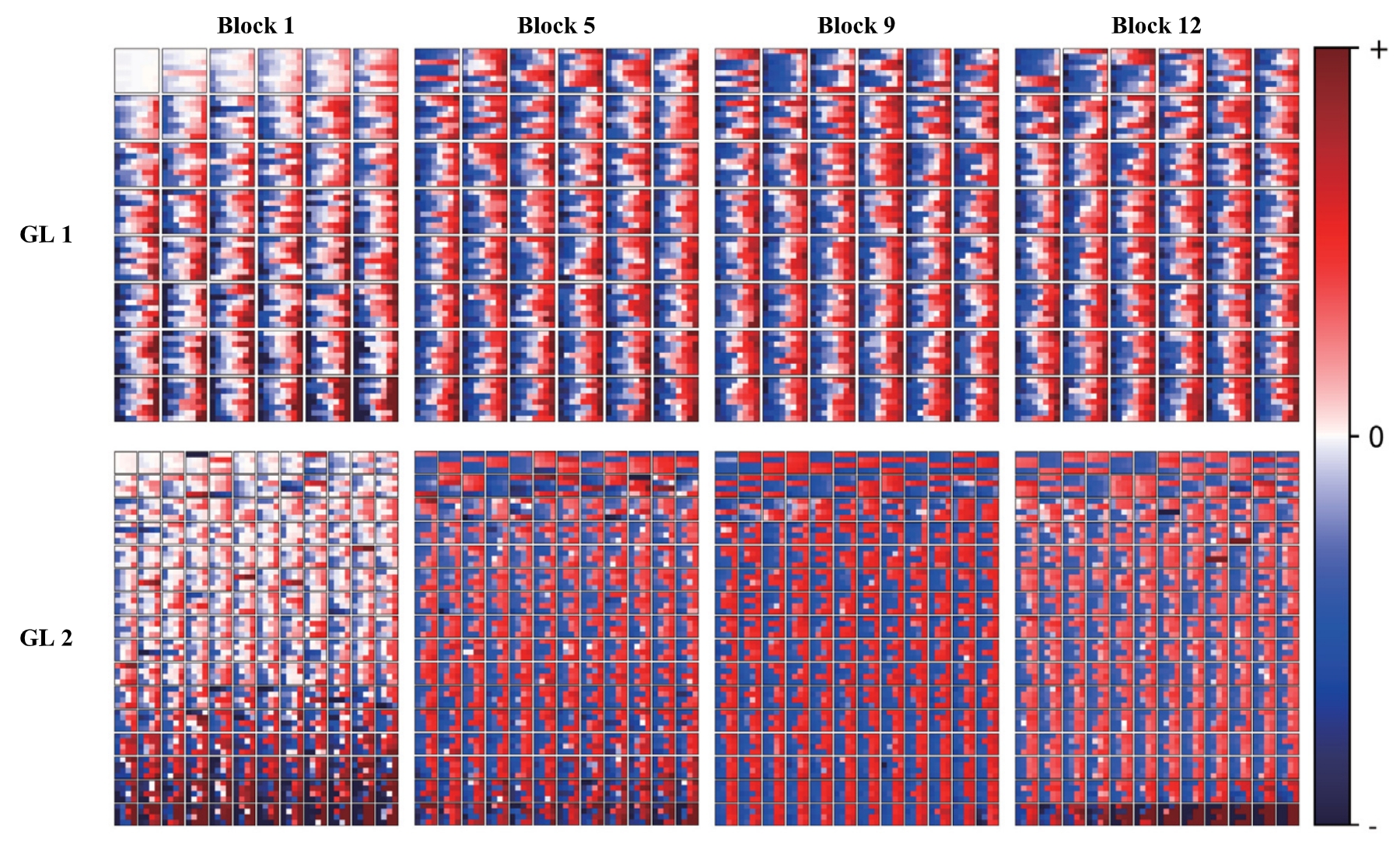
Chao Ning, Hongping Gan Pattern Recognition, 2025 Paper Code We introduce a lightweight DFC module with two grouped linear layers to learn MLP expansion and activation representations in Vision Transformers, uncover depth dependent weight pathologies, derive depth specific block settings, and demonstrate consistent accuracy and efficiency gains across architectures, for example on ImageNet 1k the PVTv2 model improves accuracy by 0.8 percent while running about 12.9 percent faster with 25 percent fewer FLOPs. |
|
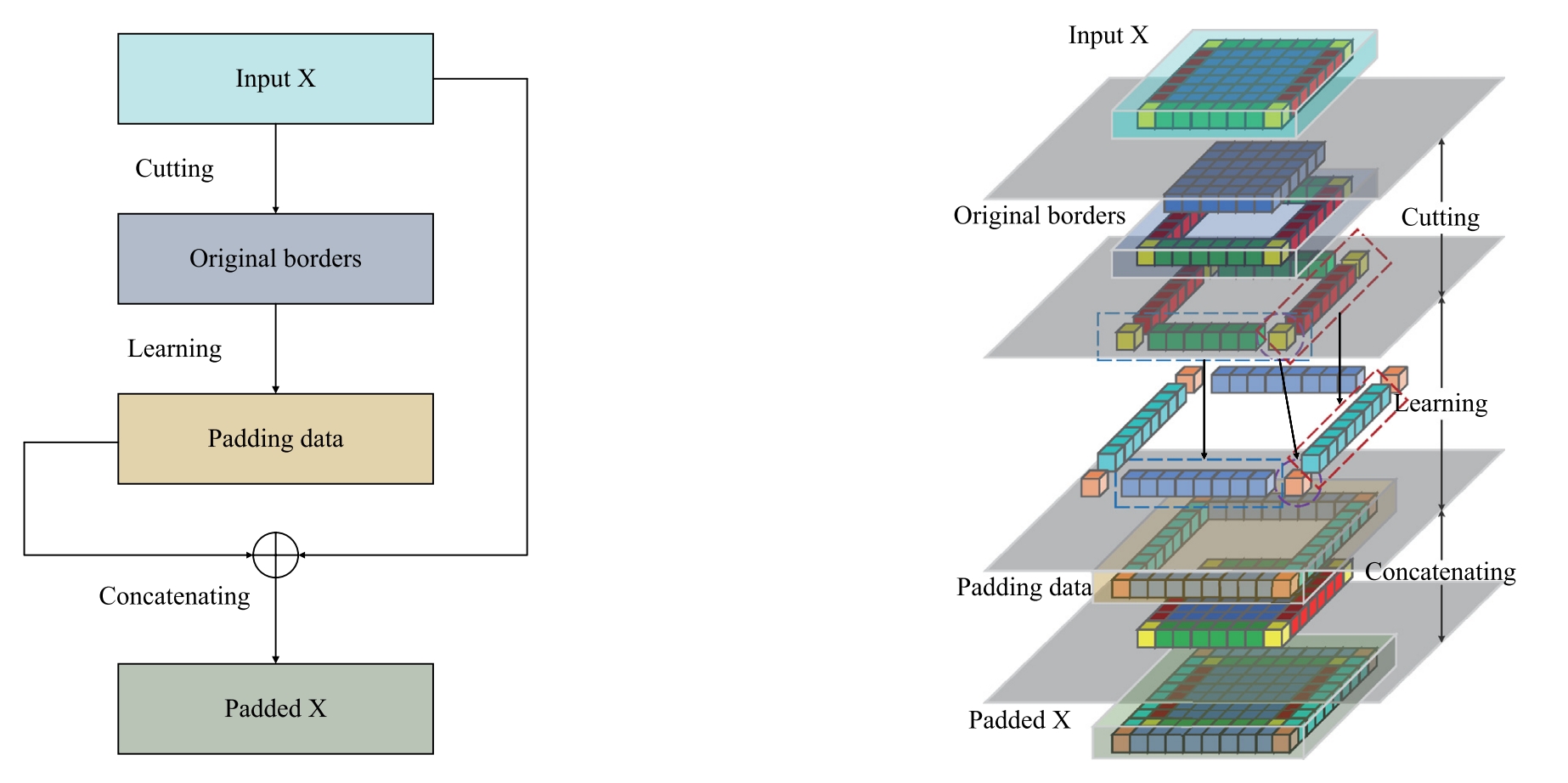
Chao Ning, Hongping Gan, Minghe Shen, Tao Zhang Engineering Applications of Artificial Intelligence, 2023 Paper Code We propose learning based padding that predicts border values from feature map context using lightweight convolution (LPC) and attention (LPA) modules, providing a generic plug and play replacement for zero padding that consistently improves accuracy on image classification and semantic segmentation across diverse backbones. |
|
|
|
|
© ChaoNing | Last updated: March 17, 2026